


Supercharged Data Strategy Leads to Successful Implementation of Data Platform: Part 2
Discover the Secrets to Build a Successful Data Platform for Better Adoption and Empowerment.

This is a two-part series. The first part accentuated the notion of “Preparation Before Building” of the data architecture. If you have not read the Part 1, here is a link1.

In the first part, we identified the following -
We observe that the main focus areas generally go missing in the strategic planning for data initiatives are-
Definition of precise objectives and outcomes
Lack of data ownership and governance
Missing KPIs for Data Quality
Guidelines on Frameworks and Toolings
We also discussed the impact of poor planning on the outcome of strategic initiatives and the result - a need for more user adoption and sponsorship to achieve the end goal.
On the flip side, we discovered the following essential elements that help pave the proper foundation for a successful Data Strategy. We called them “the secrets” -
Preparation: To build a successful Data Architecture, understanding business needs, objectives, and outcomes is essential.
The role of Data Architect: The ‘Pilot of the flight’ - who leads the organization to prepare for transformation, understand and implement strategic initiatives.
Discovery: To understand data ownership, build a common vocabulary, and develop a collaborative team culture.
The Reference Architecture: Provides the essential building blocks required to understand and document critical objectives and outcomes of the strategic initiative.
All of these points led to a “Supercharged Data Strategy” and a strong foundation with all the elements we need to start the execution plan of this data strategy.
Lastly, below is the illustration of the Data Architecture we unveiled towards the end of part - 1.
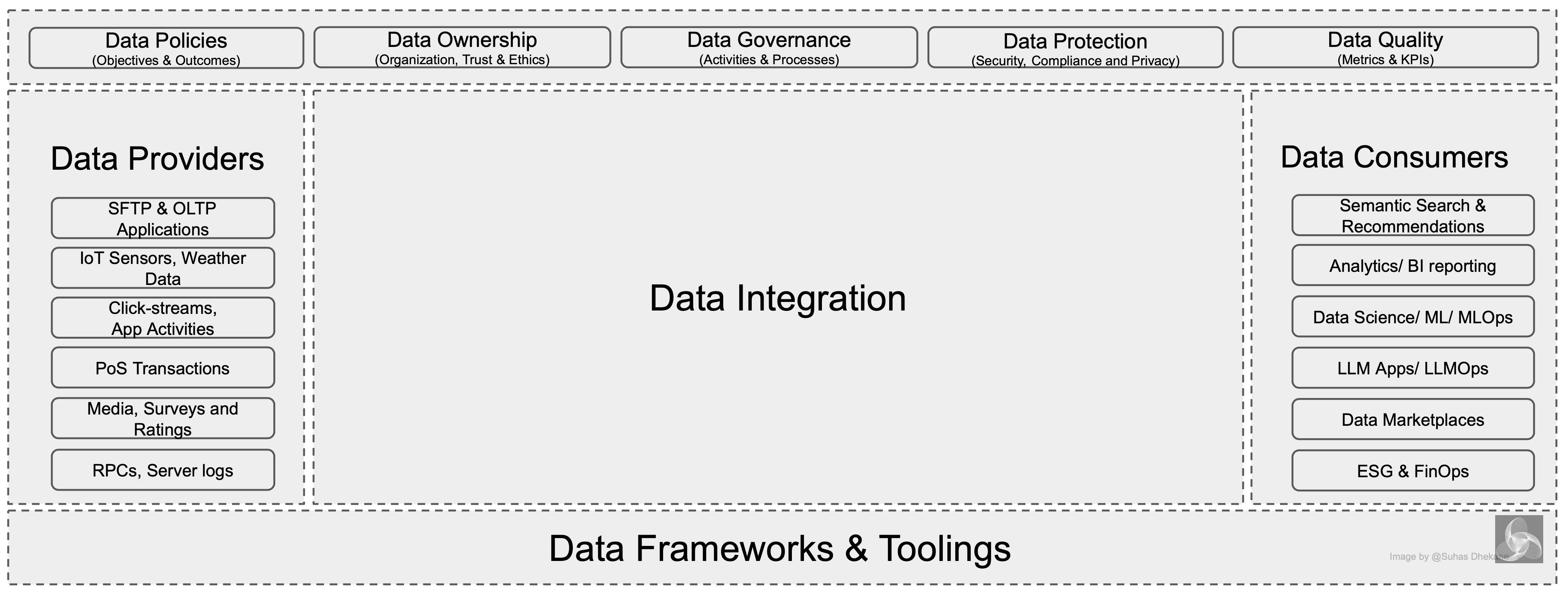
“Building upon a strong foundation.”
In Part 2, we move toward the next steps, opening up new secrets and providing guidance to overcome new challenges.
And, one more thing!
The Co-Pilot: Data Engineer
A system cannot be successful if a single person too strongly influences it. Once the initial design is completed and relatively robust, the real test begins as people with many different viewpoints undertake their own experiments.
-Donald Knuth

Best Tag Team ever - Data Architects and Data Engineers
The Data Architects continue to be the “Pilot of the flight,” as discussed in the previous article. The role of the Data Architect continues to be the lead who resolves conflicts and technology barriers and ensures that the implementation strategy aligns with the overall architecture and data strategy.
However, the Data Architect needs a co-pilot to be successful in the execution phase of the Data Strategy. The co-pilot is the Data Engineer.
Note: The term Data Engineer does not point to an individual designated as a technical lead in the organization. It refers to a community of practice where a group of Data Engineers, Data Modelers, or even Database experts collaborate to achieve the agreed-upon roadmap and help in robust design and implementation strategy.
The Data Engineer plays a vital role in doing the following -
Focus on Value realization: In the previous phase, the Data Architects helped identify and create value streams for establishing a platform for positive outcomes. The Data Engineers pave a pathway to demonstrate design patterns that will help realize value quickly with faster ROI.
Choice of Design Patterns: Identify design patterns to collect, transform, and provision data from the source to target use cases by building a Data Pipeline between the Provider and Consumer for required use cases. (See illustration below)
Build and automate: The goal is to avoid manual and one-off patterns and build Data Pipelines that deliver data on-demand or real-time, based on the consumer’s need, when the Data Pipelines are automated.
Choice of tools and technologies: As mentioned in the previous phase, selecting tools and technology should not drive the architecture and strategic decisions. However, it is precisely the opposite. The architecture decisions should guide the choice of tools and technologies to complement the selection of design patterns to implement the Data Pipelines and lead to a successful outcome for business users.
A great Data Engineering team is the secret to successfully implementing a Modern Data Platform that is successfully adopted and used to drive business decisions.

Throughout this article, we will identify other key areas where the Data Engineering team helps make the right choices and ensure the success of the Data Platform.
The Approach
In the above illustration, we have unveiled fundamental building blocks as we start discussing the execution plans. The secret of proper execution starts with these points -
The components of the Data Pipeline - collect, transform, and provision
The segregation of the storage layer and storage abstraction
The 3 O’s - Orchestration, Observability, and xOps combine to provide guidelines on framework and tooling.
We will touch each one of them as we progress.
However, the approach we take here is to focus on the following core areas that will lead to the successful implementation of the Data Platform -
A Well-Defined Execution Plan
Well-Architected Principles
The 3-O’s - Framework and Common Tooling
Let us jump into the details right away.
1. A Well Defined Execution Plan
Building upon a strong foundation requires a well-defined execution plan for long-term sustainability. The goal is to serve a more balanced business focus. It is essential to consider long-term sustainability when preparing an execution plan to understand the impact and maximize utilization and adoption. The secret is a blueprint that focuses on the following three aspects -
Purpose
Priorities
Productivity
So, what is a well-defined execution plan? A plan with a solid purpose.
As philosophical as it sounds, this is essential project management 101 -
The purpose is the straightest path to outcomes that will ensure success. Suppose the purpose of the project, its execution plan, and milestones are clearly defined. In that case, it will automatically set the right priorities. Once the program executes on the right priorities, it is bound to get more adoption, leading to productivity. The ultimate step of this equation will lead to organizations profitability.
A well-defined execution must contain a documented purpose (definition of done), further scoped based on the Data Architecture and its building blocks.
Once the scope is determined, features, capabilities, user stories, or functional/ non-functional requirements get prioritized. The prioritization also helps identify interdependencies by identifying and analyzing the Quantitative and Qualitative Factors of the use cases.
Quantitative Factors like Volume, Velocity, and Variety.
By identifying and analyzing how much data changes at what velocity and what type of data the consumer expects, it becomes easier to design patterns to cater to such needs. E.g., the volume and the velocity help determine whether a data pipeline should be batch-oriented or real-time. It can also help determine the recommended storage abstraction and underlying storage.
Qualitative Factors include but are not limited to KPIs for Quality, Transformation Needs, and Criticality.
The overall maturity of data from its raw form to its golden state goes through different qualitative factors governed by KPIs. The transformation logic to treat the data to its next maturity level is determined by the KPIs and, to some extent, by the criticality of the data element. The critical data elements are classified as sensitive (either masked or protected), mandatory, or needing a specified pattern. Such critical data elements also help determine the transformation logic within the data pipelines.
Another aspect of prioritization is the viewpoint of productivity. What use cases will help make the most significant impact and drive value? When both are equally focused, it helps with alignment, adoption, and positive outcomes.
To put all of these points together, here is a scenario. Suppose the goal is to build a self-service analytics platform (the purpose). In that case, the prioritization is on use cases that will help consolidate relevant data through data pipelines into a storage abstraction like a Data Lake, leading to efficient data analysis (productivity).
The choice of storage abstraction like Data Lake and Analytics tools that work seamlessly with the Data Lake Implementation helps further simplify the usage and adoption of the analytics platform with Data Analyst. They can independently analyze the data in the Data Lake without relying on the technical team (hence addressing the self-service aspects).
2. Well-Architected Principles
Never shoot for the best architecture, but rather the least worst architecture
— Mark Richards & Neal Ford
This topic becomes murky and highly opinionated when unpacked. Every enterprise software vendor or cloud vendor has its version of guidelines and principles for a well-architected framework. It is their viewpoint to help maximize the utilization of their software and cloud technologies. However, it does not mean those guidelines cannot be tailored, extended, or amended to the organization’s needs.
This section provides a tailored viewpoint and approach based on our discussion in Part 1. and the agreed-upon Data Strategy.
We saw in the previous part that Enterprise Architecture is a broader strategy that covers - Business, Data, Application, and Technology architectures. So, in that vein, Data Architecture is a subset of Enterprise Architecture. In general, the Data Architects (along with the EA community of practice) must define these well-architected principles for the organizations.
Data Engineers must understand these guidelines and build upon them. The role of the Data Engineer is to elaborate further the 10,000 feet view of these guidelines into a well-defined implementation plan.
Based on this backdrop, the following guidelines are essential for a well-architected framework. The Data Engineer may amend these points if they see a fit for change and when there is an alignment with the EA community of practice and Business Stakeholders.
Principle # 1: Purpose Driven Design
As discussed in the previous section, attaching a purpose to anything is the key to success. In this case, the execution of a well-defined Data Architecture. Also, as mentioned in the previous part, choosing technology, tools, and design patterns is an exercise for a later point. It should not influence the architectural design. Instead, the well-designed architecture should lead to the choice of technology. The Time is right to choose technology now.
It is foundational to design the system that solves the identified business needs. The next step in system designing is to choose technology, tools, and design patterns well-suited to solve the use cases. Time to get deeper into these use-cases
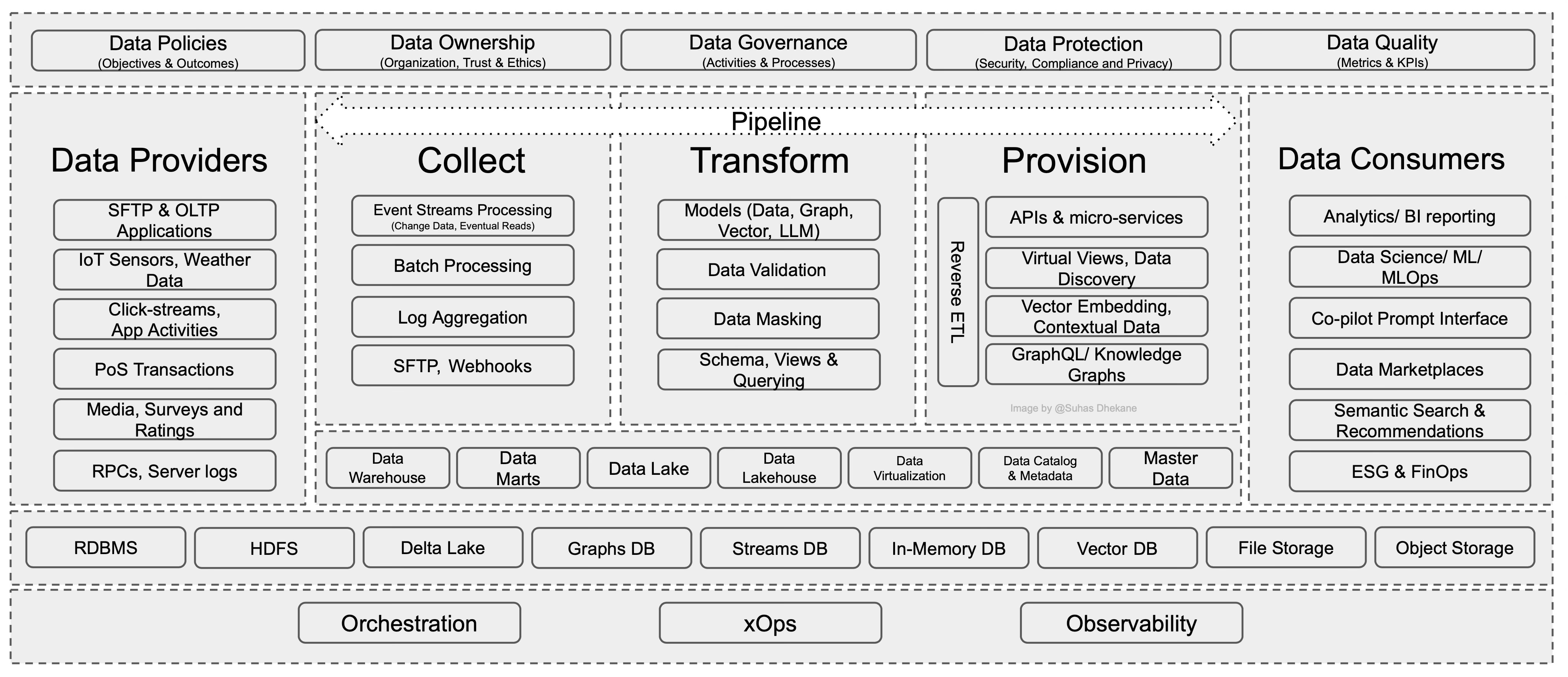
In the above illustration of Data Architecture Part 3, the data-integration pipeline is the glue to connect the data from the Data Provider to the Data Consumers. However, the contextualized data plays a critical role.
The role of a Data Engineer is to consider the data pipeline scenarios that are well-fitted for most of the use cases. The thing to avoid is building pipelines for one-off use cases.
In general, the data pipeline operates in the following steps
Collect — Store — Transform — Provision
Collect: Any modern data architecture produces data in different forms and larger volumes. The most common examples of data sources are -
Real-time changes produced through IoT Sensors, Weather, or click-stream data from the website are well suited for Event Stream processing.
Changes available at scheduled time intervals get processed in batches of transactional data from Point of Sales (PoS) systems or log aggregation from the applications logging system.
Secure File Transfers (SFTP) is well suited for exchanging data through file transfers to and from external sources.
Store: The appropriate storage layer stores the collected data based on use cases. The suitable Storage Abstraction layer, well suited for the use cases, determines the underlying storage.
Most applications and use cases use the traditional RDBMS (Relational Databases). However, as use cases evolved, storing information for faster access in non-traditional and non-relational forms has become popular. These non-relational databases are commonly known as NoSQL/ Document DBs.
Note: The book “Designing Data-Intensive Applications” by “Martin Kleppmann”2 describes the Foundations of Data Systems and provides detailed guidelines on which databases are well-suited for specific use cases.
Large organizations aim to drive business decisions through Data Analytics and Reporting. We have seen that traditionally, Data Warehouse + Data Mart well served these needs. However, in recent years, the focus has shifted towards storing any data and analyzing data in its raw form, where Data Lake and, more recently, the Data Lakehouses (a combination of traditional Data warehouses and modern Data lakes) are becoming popular production deployments using the commonly used storages like HDFS and, most recently, Delta Lake for big data processing needs.
Specialized data management needs like Master Data Management (MDM), Metadata Management, and Data Catalog are abstractions on top of the consolidated Master and Metadata information collected from enterprise applications. These capabilities are highly recommended to understand and manage critical data assets in organizations.
Another excellent use case for specialized storage abstraction is exploring the relationship between the entities not represented well by tables and documents. A specialized database like Graph DB helps traverse such relationships efficiently. Suppose the end goal is to analyze the enterprise data in the structure consisting of infinite nodes, edges, and relationships. In that case, Graph DBs provide abstraction by building a great source of knowledge about the enterprise data.
Some traditional two-dimensional simple or fuzzy query search cases limit themselves when the organization is expanding in collecting data and analyzing it in multi-dimensional mathematical rendering called Vector Embeddings. These Vector Embeddings are then used to do similarity searches (to find objects beyond texts like images, audio, and Natural Language Processing - NLP-based searches) and sentiment analysis (for detecting customer patterns and improving user experiences) that are more advanced and Artificial Intelligence driven than traditional search queries. The Vector DB, popular in modern AI-driven architecture, is very popular for such use cases.
Data Virtualization is a subset of broader Data Management use cases. Data Virtualization is beneficial for abstracting data from different internal or external sources.
Transformation: The primary responsibility of a transformer is to transform data from raw or any intermediary form to a more structured and consumption-ready form. The concept of representing data in structured form is called Modeling of data.
Traditionally, the Data Models evolved from Conceptual to Logical to Physical form in stages. Each stage added more structured information to the data model based on manually performing data analysis.
In modern architectures, Graph Models, Vector space Models, and Large Language(LLM) Models are represented using mathematical formulae based on a data-driven approach, also known as machine-learning (ML) models.
Data representation (manually or ML-based) in data models may also need data transformation from its raw form to evolve and contextualize the data suitable for the data consumers to consume.
Data Transformation rules can be of many forms, like validation checks for email phone numbers, managing and masking sensitive, confidential information like SSN or Gender, or simply performing sufficiency checks like null-check and length-check. These are the most common transformation rules. Organizations may have more advanced rules to support business needs.
The Data Engineers role is to work with the Data Modeling and Data Governance team to understand and implement all the transformation rules.
The transformed data also uses the same storage and storage abstractions layer we discussed previously. The Data Virtualization and the broader Data Management Layer become more relevant as the data starts taking the shape of enterprise-wide consumption.
Provision: The transformed raw data is made available through provisioning. It acts as a gateway to clean data for consumption.
The role of the Data Engineer is to provide data on well-suited end-points for consumption.
In modern software design, Microservices Architecture (MSA) and Application Programming Interface (APIs) are the most common ways to interact to perform complex functions. They are well-suited for use cases with a real-time request/ response model where the consumer can pull/ request the data needed. The consumer can be an internal consumer within the enterprise. For external consumers in the Data Marketplaces, API Gateway provides a proper mechanism to share the correct type of data with the appropriate entitlements and monetize it.
The Data Virtualization layer also plays a vital role in abstracting, consolidating, and transforming the data from various sources and creating virtualized views to share data for operational or analytics purposes.
Similarly, vector embeddings, graph models, and LLM models are available via a prompt interface to enable live interaction with enterprise data to unleash use cases based on AI to do sentiment analysis, similarity search, Natural Language Processing search, or relationship-based search.
Another aspect of the Data Pipeline is ‘Reverse ETL.’ It is a niche use case with independent vendors excelling in reverse ETL. In reverse ETL fully processed, clean data is relayed to the Data Providers to take advantage of clean data. One example that can be data from the MDM use case is the Co-existence Design Pattern defined by Gartner for Multi-domain MDM implementations. In short, it consolidates data from various sources into MDM for mastering. Once the MDM system masters the data, the golden records automatically ETL through the upstream sources with MDM attributes and Golden MDM ID for further use.
Principle # 2: Operation Excellence
“Everything fails, all the time”
Werner Vogels, Amazon CTO.
The next focus is committing to implementing the platform correctly while consistently focusing on the end-user experience.
It is fundamental for end-user experience to have a data platform that is reliable, scalable, and easily maintainable.
Reliability is for more than just for highly critical systems like nuclear plans or air-traffic controllers.
The role of a Data Engineer is to strive for optimal reliability for better adoption of the data platform. Bugs in critical business applications can cause longer downtimes and business continuity issues, affecting reliability.
Chaos Engineering is the discipline of experimenting on a system to build confidence in the system’s capability to withstand turbulent conditions in production. Anticipate failures. Alongside the Chaos engineering, embracing self-healing capabilities helps in an automated recovery from failure scenarios. Such advanced mechanism helps in achieving operational excellence.
Minimizing Disruption: Deploy new features and fixes with minimal disruption. The Data Engineers must plan for frequent, small, and reversible changes to ensure minimal platform disruption. Such discipline makes the platform easily maintainable and reduces the time-to-deployment for newer features and capabilities that end users await.
Automation: Automation is implemented in application and infrastructure disciplines to code the entire environment. Scripting automated operations procedures help respond to events for consistency and eliminate human errors. The Data Engineers must embark on automation to cater to the needs of highly scalable applications.
Observability: A stable data platform that is resilient for a quick recovery from catastrophic failure. Implementing Observability helps understand the workload patterns and plan for actionable and proactive insights for platform stability. The two common forms of Observability are Application Observability and Data Observability. Note: We discuss Observability in the next section.
Principle # 3: Efficiency and Optimization
A purposeful design led to a platform implemented consistently for operational excellence. The time is to focus on performance efficiencies and cost optimization.
It is an ongoing exercise to thrive for optimal system performance and total cost of ownership (TCO). Even if the platform is reliable today, it is guaranteed to be different. Increases in user or data volumes are common causes for the platform’s performance to degrade.
With automation and observability, the Data Engineers must proactively prepare the platform to auto-scale up and down to serve the changing business needs. Hence, this is an ongoing exercise. Having optimal performance is essential for broader adoption of the Data Platform.
With larger organizations migrating workloads to the cloud, the role of the Data Engineer is to work with IT operations and Finance team to establish a shared responsibility model called FinOps (note - we will cover this in the next section) to take advantage of cloud governance tools and analyzers to understand and tune the utilizations automatically.
The Data Engineers must embrace serverless technologies to manage the optimal use of backend components that are required based on trigger events.
Predicting the operating cost or TCO based on ever-evolving usage patterns and business needs is difficult. The above core focus areas - automation, observability, cloud governance tools and analyzers, and embarking advanced capabilities like serverless technologies- help understand the overall workload probability of the data platform to help optimize the TCO without locking into specific and on-time infrastructure, application, or cloud vendor configuration setups.
Principle # 4: Secure
The data is the most critical asset for any organization. Security is the ultimate principle driving business adoption regardless of how reliable, scalable, and purpose-driven the data platform is.
At a high level, security protects data, systems, and other assets from internal and external misuse.
As an overarching practice, security is embedded in the entire ecosystem of the organizations, and it must be centrally governed to provide proper access to people, systems, and applications.
The Data Engineers are vital in embedding security protocols and application and data layers.
Implement a strong identity foundation centrally governed within the data platform with the principle of least privilege and enforce separation of duties with appropriate authorization for each interaction with resources within the data pipeline.
Protect data in transit and at rest using industry-standard encryption, tokenization, and key management policies.
Observability is critical in monitoring and auditing actions and usability patterns to identify or flag anomalies in the log data.
Prepare for an incident by having incident management and investigation policies and processes that align with your organizational requirements.
Run incident response simulations and use tools with automation to increase your speed for detection, investigation, and recovery.
3. The 3-O’s: Frameworks and Common Tooling
The standard tooling and frameworks are foundational. In most cases, they are often neglected or retrofitted into the implementation at a later stage.
Throughout the discussion of a well-architected framework, we touched upon these points. However, I wanted to separate them in this section to provide the proper attention and put them in the correct context.
The 3-O’s that glue everything that we are discussing in this article is as follows -
Orchestration -
Orchestration is the coordination between multiple data flows running simultaneously and collecting and transforming by interacting with the providers and storage abstractions to provision data to the consumers.
Orchestration tools are essential in executing complex tasks requiring heavy lifting to run the data pipeline reliability. These tools are typically separate from data management or machine learning tools.
The lack of such orchestration tools leads to inconsistent efforts of manually deploying, running, monitoring, and managing data pipelines by the data teams.
As the complexity of data architecture grows to serve different business needs, keeping track of each data pipeline becomes difficult. Moreover, manual processes become inefficient in keeping track of end-to-end data movement, thus creating silos of data resulting in data duplication.
Various tools like Apache Airflow or Metaflow (by Netflix) are invaluable in providing the centralized orchestration to keep track of each data pipeline, its purposes, its point of interaction, and integration, resulting in increased efficiency, improved scalability, flexibility, security, and collaboration.
Observability -
Developing trust in the data platform through the right processes and optimal data quality is vital to delivering enterprise data to the organization’s reliability. The essential step is to understand the health of data continuously.
Observability is a broader term coined initially for software applications; however, it is relevant best practice for the data teams as an essential first step in Data Observability.
It is an interconnected approach that binds the entire end-to-end data lifecycle to understand the health of the data at each stage.
Having observability makes audits, breach investigations, and other
possible data disasters much easier to understand and resolve
The observability framework makes measuring the ROI of data and data quality processes efficient. An unreliable data platform that results in untrusted data leads to compliance risk, lost revenue due to costly downtimes, and erosion of end users’ trust in the platform. Tracing the ‘Time to incident detection’ (TTD) and ‘Time to incident Resolution’ (TTR) through the observability framework can detect the cost of downtime due to insufficient data and have a framework to improve data health.
Note: The book “Data Quality Fundamentals” By Barr Moses, Lior Gavish, and Molly Vorwerck3 has a detailed and prescriptive approach to data observability.
xOps
Yes, the Ops suffix is hard to keep up these days! 4
xOps generalizes various disciplines and their seamless interactions with IT operations (Ops) to define better processes and govern the quality and faster operations. Below is the illustration of a combined view of the most common Ops processes tailored to our discussion.
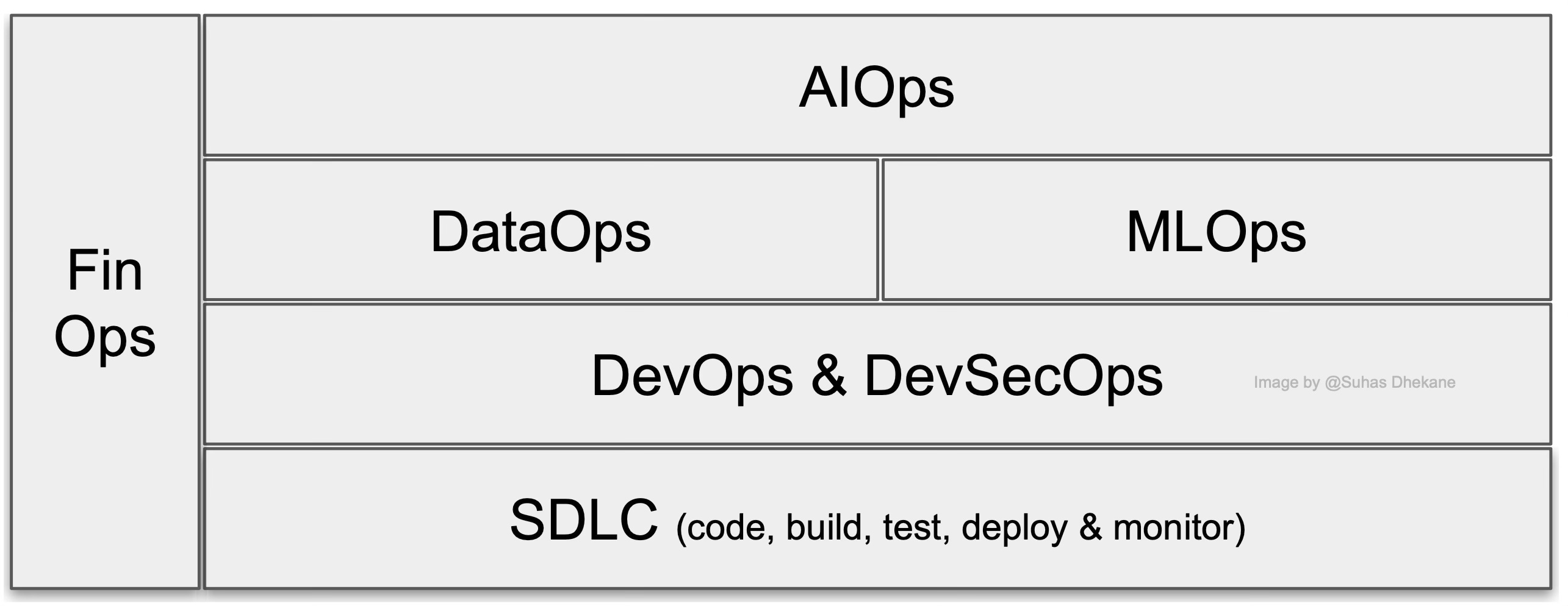
DevOps: For the uninitiated, it all started with DevOps - combining the software development (Dev) and IT operations (Ops) practices to streamline and shorten the development lifecycle by integrating CICD (continuous integration and continuous delivery) methods to manage and maintain the code deployment with high quality.
DevSecOps - While DevOps focuses on the efficiency of SDLC processes, DevSecOps focuses on security as a shared responsibility between Dev and IT Ops processes.
DataOps - DataOps is a collaborative data management practice to streamline the health, integration, and flow of data across the enterprise. With the advancement of Data Analytics, it is essential to build repeatable and continuous delivery of data and data management processes. This discipline is inherited from DevOps best practices.
MLOps - Similar to DataOps, MLOps has inherited the best practices of DevOps for machine learning. It streamlines machine learning models' development, deployment, governance, and intersection of people, processes, and platforms.
FinOps5 - Like Security, cost optimization of IT workload has become a shared responsibility with the advancement of cloud infrastructure. FinOps works on the lifecycle phases of Inform, Optimize, and Operate to focus on streamlining the budget management and forecasting IT workload cost to allocate and govern the cost of various disciplines, provide show-back analysis of usage patterns, and detect and remediate anomalies.
AIOps - Coined by Gartner, AIOps6 focuses on eliminating manual and error-prone tedious Ops processes to transform into streamlined, automated operational workflows that provide real-time monitoring and are built with capabilities such as natural language processing (NLP) to gain deeper insights into complex data issues anomalies, and patterns for predictive actions and remediations. On the other hand, ChatOps integrates AIOps capabilities with a prompt interface for better collaboration, communication, knowledge sharing, and empowerment through automated roles for task executions and incidence responses across all disciplines.
In conclusion, the 3-O’s framework enhances the core capabilities of data pipeline management. It takes the end-user experience to the next level by augmenting AI-driven orchestration, building trusted data through continuous monitoring using observability, streamlining processes, increasing efficiencies, collaboration, governance, and effective management of resources through shared responsibilities across all data platform disciplines.
Conclusion -
To conclude the two-part series -
Starting with supercharging your organization with essential components of Data Strategy to drive the right Data Architecture for successful outcomes
Building upon the supercharged Data Strategy to define a fine blueprint for execution, a well-architected framework to make the right design and technology choices, build a robust, scalable, flexible, reliable, and maintainable data platform that is secure and excels in all the operational processes.
Finally, we saw the 3-O’s (Orchestration, Observability, and xOps) augment AI-driven orchestration, continuous observability for healthy and trusted data, and xOps for streamlining Ops processes and building a collaborative ecosystem.
Throughout this journey, we uncovered often neglected secrets and elaborated on the key roles and responsibilities of the flight pilot, i.e., Data Architect, and the co-pilot, i.e., Data Engineer.
This helps navigate your organization's Data Strategy and implement a successful Data Platform.
I would love to hear your success stories, lessons learned, and experiences with the Data Platform implementation using the Modern Data Architecture.
References and recommended further reading: