

Supercharge Your Data Strategy for Outstanding Value Creation - Part 1
Discover the Secrets of Modern Data Architecture and the Preparation for Better Execution & Collaboration.
This is a two-part series. The first part (this article) focuses on “Preparation Before Building” the data architecture. It also introduces the core building blocks of data architecture and its success criteria to achieve an outcome-driven value chain.

Many flavors of Modern Architecture for Data are available on the internet. They are very specific to infrastructure, tools & technologies. But, there are very few architectural viewpoints that provide the following details-
Clarity on objectives and outcomes: What business problem is a data architecture solving?
Data ownership & governance: Who are the stakeholders responsible for data trust and ethics?
Documentation on key metrics for data quality: How is the quality of data measured? What value a data assets carry?
Guidelines on frameworks & tools: Which tools, technologies, and patterns provide the right scale without over-engineering the solution?
In short, the holistic view of understanding essential information from soup to nuts is missing. Moreover, some of them represent design patterns because they do not connect the outcomes to the objectives.
For every strategic initiative, organizations must invest in reference architecture development. This provides a holistic viewpoint and guidelines to the stakeholders when needed.
Without such a viewpoint and guidelines, the following problems may arise, leading to failure of implementing the strategic initiative -
Lack of holistic understanding of objectives and outcomes. Result: More than 80% of Big Data projects fail to deliver outcomes.
Challenges with communication and a common vocabulary. Result: Introduces data silos and trust in data.
Lack of interest and engagement from stakeholders & sponsors. Result: affects adoption and usage of the platform.
Poor Data Quality and inadequate governance, missing ownership, and segregation of responsibilities. Result: More than 87% of data-science projects are never deployed.1
Over-engineering the solution by misusing tools & technologies: Result: More than 97% of Data Engineers burn out on making the tools work to achieve promised outcomes. Perhaps the right architectural foundation is missing in such cases.2

Hence, it is important to have a well-defined reference architecture that aligns with strategic initiatives. This will ensure success and guidance when required. This paves the foundation for -
understanding a common goal,
embracing federated responsibilities,
promoting collaborative team culture, and
better execution and user adoption with a well-understood strategy.
A reference architecture connects architecture building blocks to strategic initiatives.
So, what is our end goal when we build any architectural representations?
The short answer is to develop an architectural representation that builds continuous value streams that drive business outcomes to generate faster ROI and make data strategies successful.
Role of an Architect
An Architect is one of the most critical roles for the successful implementation of any strategic initiative.
The Architect must understand the organization’s focus, objectives, expectations, and outcomes. This helps the Architect in navigating the enterprise through the journey and achieve positive outcomes.
An Architect must ensure that any derived design patterns align with the reference architecture.
A choice of tools must be an exercise for the latter part of the architecture and design processes. A choice of improper tool will lead to the failure of implementations. It is important to gather knowledge and understand the expectations before jumping ahead. This point is well explained by the best-selling author Joe Reis in his article linked in references.3
Throughout this article, there will be references to other roles and responsibilities of an Architect.
Note: The term Architect does not point to an individual designated as an Architect in the organization. It refers to a community of practice where a group of Architects is drafting a roadmap for a common goal or strategic initiative.
One of the secrets to better execution and collaboration lies in the hands of the captain of the airplane, the Architect, in this case. An Architect must follow the notion of -
“Prepare Before Building”.
Reference Architecture:
A reference architecture4 provides a template solution for an architecture domain. There are 4 types of architecture domains in an enterprise architecture framework. They are -
Business
Data
Applications
Technology (or infrastructure for simplicity)
In this series, we are focusing on the #2 Data Architecture.
A reference architecture also provides basic building blocks to further refine specific architecture and design patterns, and solution architectures based on targeted use cases.
Data Architecture:
Data Architecture aims to set data standards for all its data systems as a vision or a model of the eventual interactions between those data systems. It addresses data in storage, data in use, and data in motion; descriptions of data stores, data groups, and data items; and mappings of those data artifacts to data qualities, applications, locations, etc. 5
Data Architecture encapsulates the overall data strategy, data frameworks, and tooling associated. It is aligned with the Data Maturity6 assessment of the organization. The architecture provides solutions to achieve target Data Maturity. Based on this, below is an abstract view of Data Architecture.
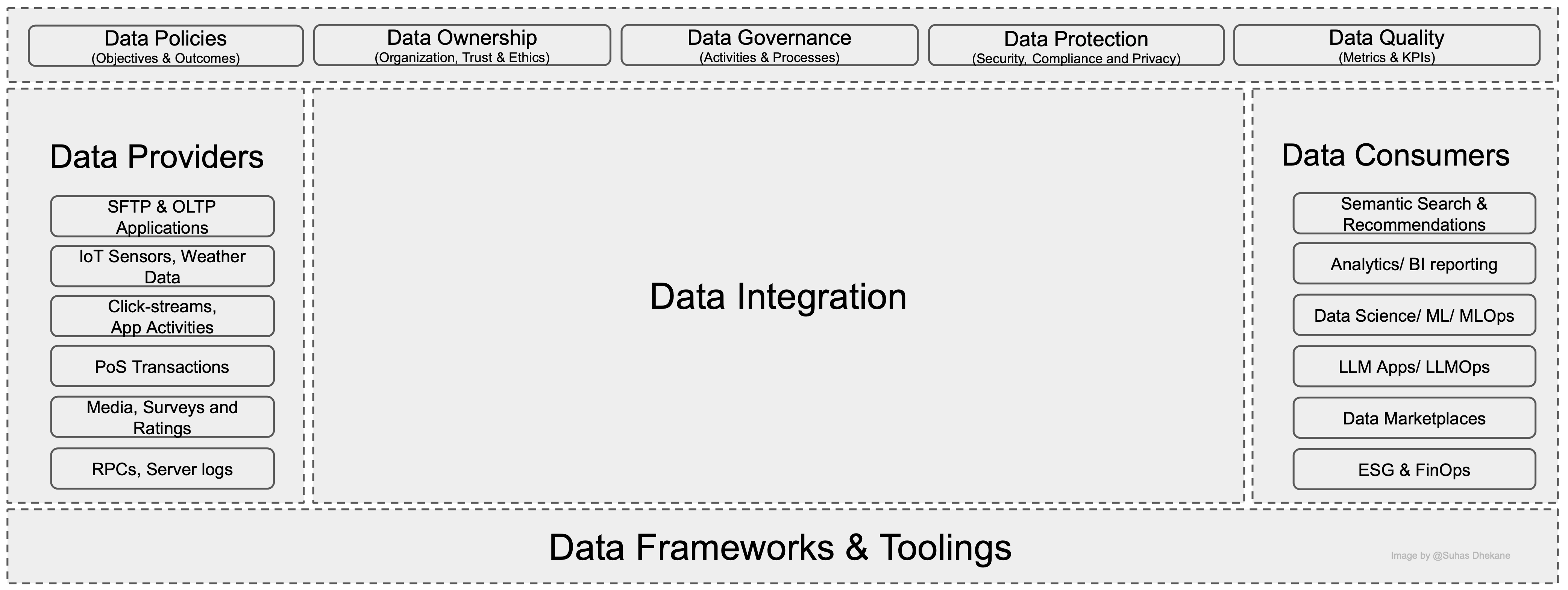
Abstract View:

The abstract view provides a basic building block representation for the data architecture.
Data Strategy
Data Providers
Data Consumers
Data Integration
Data Frameworks & Toolings
These core components are essential for building any data architecture patterns.
The reference architecture for data starts with knowing the organization's Data Strategy.
The Data Strategy provides guidelines on data handling to ensure necessary processes are in place to manage the data.
Building Block of a Data Architecture
Data Strategy:
"Strategy is not the consequence of planning, but the opposite: its starting point." — Henry Mintzberg, management thinker and “Enfant terrible” of strategic planning theory
Any organization requires a well-defined data strategy for capturing the details of data initiatives and measuring their outcomes.
A data strategy is similar to a business plan that defines how an organization produces, integrates, and consumes data. The data strategy fits into a broader business strategy of an enterprise.
An Architect must know and understand the details of the data strategy before developing any further variants of Data or Solution Architecture. The following are various areas for understanding a data strategy to ensure the focus is on continuous value creation and business outcomes.
Data Policies:
The first step is to start with understanding the high-level objectives and outcomes.
Before determining the high-level objectives and outcome, the organizations go through a preliminary step of understanding and documenting the overall data maturity across the organizations. This helps in documenting the as-is state, the gaps, and the expected effort to transition from the as-is state to the target state maturity. The target state maturity provides the outcomes the data strategy will drive towards.
As you can see, a larger portion of the work is done in the preliminary state; hence, the data strategy also fits into broader enterprise architecture initiatives. The baseline, for doing this exercise, is to understand and align with the strategic business initiative that is defined and documented as a narrative by the executive business teams.
When an Architect is aligned with the objectives and outcomes expected by the organization, it brings clarity to the execution plan. The end goal becomes clear, and so does the big-picture view.
Data Ownership:
The next step in defining a data strategy is to understand the ownership of the data. The focus is on getting an understanding of data organization, trust & ethics.
A key discovery for an Architect is getting to know who the key stakeholders for data are, what data assets they own, and how they handle these data assets. Having this information before the entire architectural roadmap development kickstarts would expedite the process to some extent.
A lot of data-enabled organizations have started following a mesh organization structure-
A Federated Governance structure across the enterprise for interoperability purposes
A fully functional data team governing the ‘Data-as-a-product’ or ‘Data Product’ notion.
Note: For a full understanding of the concept of Data Mesh is well-explained by Zhamak Dehghani in her original writeup on “How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh”7
A clear understanding of data ownership also helps with the following aspects-
Defines an efficient decision-making model for effective communication and reporting
Federates the responsibility of data and other teams to feed into an effective governance structure
Documents and spread awareness of ethical practices of handling confidential, sensitive, and privacy responsibilities on critical data assets.
Builds trust in both internal and external stakeholders, customers, and partners to build a trusted governance team.
Data Governance:
Both the Data Policies and the Data Ownership are fed into the overall Data Governance to define the end-to-end activities and governance processes.
The data governance process documents the end-to-end data lifecycle management from data acquisition to how the data is archived or purged. Each step of the process lists activities involved in managing data control, availability, and usability. The data owners play an important role in the data governance process. They ensure proper governance & change management procedures of data updates throughout the life cycle by reviewing, approving, and rejecting changes based on agreed-upon governance rules.
Effective data governance process provides numerous benefits to the organization including
Implementing cost control measures
Identifying and mitigating data risks
An Architect must clearly understand -
The lifecycle of data and how it is created, processed, used, and archived.
The overall data governance flow through the data lifecycle journey
The linkage of Data Policies and Data Ownership to the Governance flow.
The internal standards to manage and maintain data.
Overall, Data Governance is a very deep and essential part of the Data Management process; however, these are only high-level views to clarify the requirement of Data Governance for the successful development of Data Architecture.
The author ‘Piethein Strengholt’ in his book ‘Data Management at Scale’ has an entire chapter dedicated to Data Governance and essential dimensions for setting an effective Governance.8
Data Protection:
As discussed in the above point, the Data Policies and Data Ownership feed into the Data Governance process to define the organization’s internal standards for Data management. Data Protection focuses on defining the steps to protect data and make data sharing reliable, trustworthy to comply with a set of external standards.
There are many Data Compliance Standards and Guidelines established to govern the usage, handling, processing, and purging of sensitive PII, PHI, and other confidential information that organizations collect, store, and used in their business processes. For Example, the well-known and established GDPR, CCPA, BCBS-239, or the proposed new EU AI Act.
Many organizations require being compliant with these standards
For effective risk aggregation, risk reporting, and enhancing the risk mitigation processes.
To effectively handle Data Privacy and consumer data protection across the enterprise and report on it
Before any development of Data Architecture, an Architect must know the organization's Data Compliance and Protection strategy. Acquiring such knowledge from the Data Governance team avoids a lot of re-architecture and rework later.
Failing to build a compliant Data Platform for data-sharing and reporting, causes data trust issues, silos, and lack of engagement of key stakeholders, leading to failure of data strategy.
Data Quality:
The fact is, ‘bad data’ and ‘poor data quality’ has a long history since we started collecting data. A direct impact of poor data quality is ‘data downtime’. This results in business continuity problems for any organization. A less mature data organization takes a reactive approach of ‘fire fighting’ to fix data quality issues. On the other end, a more mature data organization may react to alerts, notifications, or prediction of ‘data downtime’.
As an Architect, it is important to understand the impact of bad data and poor data quality. But, it is also necessary to understand the metrics on basic data quality functions, i.e. Accuracy, Reliability, and Completeness.
The impact of data downtime increases as more data is acquired, accessed, and analyzed by data teams. It is essential to implement data quality checks on both ends when the data is acquired and accessed by various pipelines, and also when data is consumed for analysis.
Note: Just like Data Governance, Data Quality is a vast topic. In the context of this article emphasizes the importance of why an Architect should be prepared to understand the impacts of ‘Data Downtime’ and poor data quality.
Data Provider:
Data Providers are the 'system of record' - where the data originates. They are the trusted source of the data. The most common data-providing applications are software, files, and other endpoints.
Some data sources are internal to organizations, like OLTP or OLAP systems9. Other data sources are 3rd party vendor sources or SaaS providers. The data or streaming pipeline must have easy access to source data or vendor-specific data as needed.
Nowadays, critical data originates from real-time endpoints like IoT Sensors. Depending on the industry vertical, these sensors can be anywhere from edge devices, machinery, healthcare equipment, weather sensors, etc.
Event streams are also essential data sources. They are most common in B2C industries like Retail, Hospitality, restaurants, etc. It is a necessity to collect and analyze consumers’ sentiments about products and services from clickstream social media, surveys, and ratings.
All these data sources are either deployed on-premise infrastructure or on the cloud infrastructure.
The Data Providers must be able to produce data as per defined data contracts. For example, data is available in batches with defined column structures or as a real-time source with a defined message format.
The metadata repository must have a registry of these golden sources. It can also provide detailed schema definitions for the golden sources. These source systems must provide the data definitions, glossary information, and classification for the critical data elements within the schema. This is a great way to harvest the required metadata & build the enterprise Data Catalog for golden sources.
Data Consumer:
The responsibility of a Data Consumer is to consume the data in the business context. Direct integration between the data providers and data consumers would not make the data available in a consumable form. Hence, organizations invest in various pipelines to integrate data providers and consumers in a decoupled and scalable pattern.
The organization makes several other business investments in use cases to analyze data risks and drive business decisions. This is why there is a need to make the data available in a consumable form.
The first-generation data architecture provided centralized access to data, in the data warehouse, for BI reporting needs.
With exponential growth in data, there is a need for advanced architecture patterns to serve the data analytics needs, such as -
Machine learning (ML) models on the data to identify anomalies and risks, predict trends, and gain competitive advantages for business growth. MLOps creates an intersection between various aspects of ML, like development, validation, deployment, and governance of ML Models.
Advancements in technology and Artificial Intelligence (AI) have made it easier to scale and integrate Large Language Models (LLM). This allows us to interact with data using natural language, Vector Spaces, and Graph visualizations. It uncovers unexplored use cases like analyzing sentiments through Natural Language Processing (NLP), or effectively searching media, and images based on semantics and not text through Vector Embeddings. Such advancements provide the required scales to analyze billions of records efficiently.
Data continues to be a strategic asset to data-enabled organizations. Making the most critical Data Products available in the Data Marketplaces for external data consumption, is an ultimate target for many organizations.
Generate required reports for elevating the organization’s status and putting required governance to act responsibly -
Environmental, Social, and Governance reporting (ESG) to elevate the status of organizations and govern them to act responsibly.
Integrate data with other systems to drive shared responsibility to optimize savings, and manage cost through a well-known FinOps.
The data-consuming applications also register the consuming targets to the metadata registry. This captures the complete data movement from source to target, providing detailed horizontal lineage from source to target.
An Architect must ensure the scalability in architecture patterns as new data sources are acquired to unleash new use cases.
Between the Data Provider and Data Consumer, responsibility segregation is very essential. There was a loss of ownership in the past due to point-point integration across the systems.
The distributed approach, in modern architecture patterns, drives ownership. The Data Provider handles registering the trusted golden source. The Data consumers prepare for the right data consumption. A critical building block that connects the data provider and the data consumer is the data integration layer. It is a larger chunk of this architecture and would need an entire write-up dedicated toward deep-diving into Data Integration. However, to proceed with the abstract view of the reference architecture
Conclusion:
As we conclude Part -1, the key secrets to successful data strategies are as below
The role of an Architect is to navigate through the process
The importance of preparation and discovery is to have clarity on objectives and outcomes, ensure effective communications, and common vocabulary
Architecture development is an evolutionary exercise. This can be seen by looking at the Abstract View and below the Capabilities View of the architecture diagram.
Provide a big-picture view and clarity but also help to identify any gaps that may cause delays or other adverse effects during the build phase of the project. This will also help in managing project costs and pave the pathway to success.
The story continues to unfold further, in Part 2, and introduces the remaining 2 building blocks, i.e. Data Integration and Data Framework & Tooling. Here is a discovery so far… I hope to see you in Part 2.
Links for further readings and References